The Road to Convolutional Neural Networks
An Oversimplified Explanation of Classicial to Deep Learning in Computer Vision
MAR 16 · 2026 · 6 MIN READ

Disclaimer: These are rough notes based on lecture slides from the Computer Vision course I am currently enrolled in as of March 2026. Permission to share this material was obtained before publishing this article.
In-text hyperlinks throughout this article serve as contextual and prerequisite learning resources. They are included for readers to explore underlying concepts but are not part of the formal reference list, as they were not directly used in the derivation of the material presented.
Computer Vision before Convolutional Neural Networks (CNNs)
Before the rise of deep learning in machine learning and computer vision, most systems relied on hand-designed (or hand-crafted) features instead of learning features directly from images.
An engineer would manually define methods for a computer to detect useful patterns, such as applying manual edge detection or using algorithms like SIFT or HOG.
Within our traditional pipeline:
- Take an input image.
- Run the input through the hand-crafted feature extraction phase.
- Feed the resulting feature vectors into a separate, trainable classifier.
- These classifier models include Support Vector Machines (SVMs), or nearest neighbor algorithms.
- Output prediction based on the classifier.
.jpg)
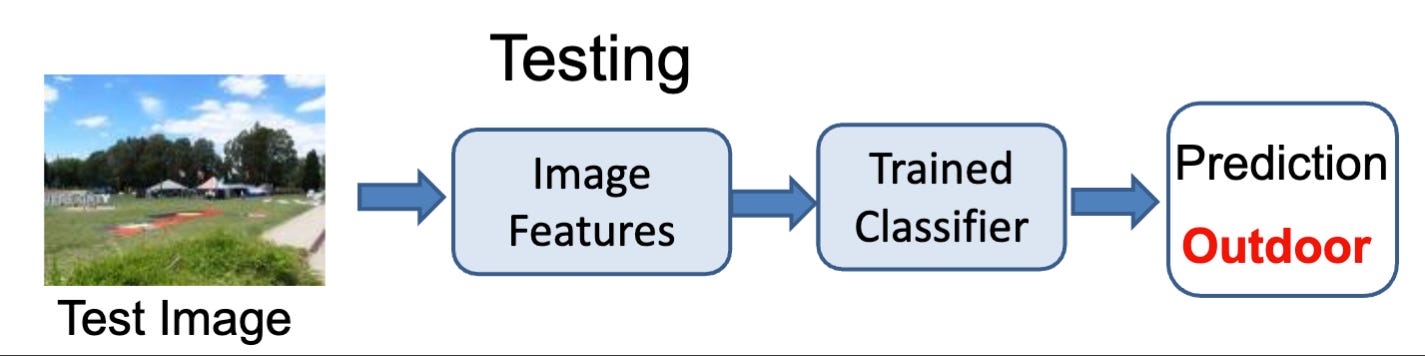
This old pipeline, however, had glaring limitations. The performance of the outputs/predictions was completely dependent on human ingenuity. This means that performance depended heavily on the manually designed features. These systems were often less flexible and less powerful than the modern deep learning approach.
Feature Learning Revolution
The shift in modern computer vision from manual to automatic feature engineering changed our approach to CV pipeline construction. The breakthrough moment came in 2012 with AlexNet, which demonstrated that deep convolutional neural networks trained on GPUs could dramatically outperform classical vision pipelines.
.jpg)
In our old systems, which we designate as shallow architecture:
- They typically used a small number of processing stages.
- Was reliant, as stated earlier, on human-designed features.
- Did not use and learn from rich hierarchical representations from raw pixels.
Within our new systems, which we will call deep architecture:
- It stacks many layers of processing units on top of one another.
- Instead of relying on a human-engineered definition of what constitutes a
shape or pattern, the networks are trained
"end-to-end" to learn a feature hierarchy jointly from raw pixels all the way to the
final classifier.
- The lower layers learn simple patterns.
- The middle layers learn more complex structures.
- Higher layers learn more abstract, object-level features.
.jpg)
CNN Building Blocks
.jpg)
There are 3 main / core components for a Convolutional Neural Network (CNN):
1. Convolution
- The convolutional layer uses learnable filters to scan across the image spatially, computing the dot products.
- These learnable filters operate on the scanning of the image via local connectivity, which means that a neuron within the neural network only looks at a small chunk of the previous layer.
- Then, the learnable filters are applied and reused across the whole image in different parts, which is called shared weights.
- Thus, the network can detect local patterns within images, such as edges, corners, textures, and simple shapes.
- This is important because convolution helps detect patterns regardless of where they appear in the image, greatly reducing the number of parameters needed in the pipeline compared to fully connected approaches, which makes feature detection more efficient and scalable.
.jpg)
2. Rectified Linear Unit (ReLU)
ReLU is a simple nonlinear activation function in which, mathematically, it turns all negative values into while keeping the positive values unchanged:
Adding nonlinearity allows a network to approximate highly complex functions:
- This simplifies backpropagation and speeds up learning, which is especially helpful when training deep networks.
- And, it combats the vanishing gradient problem, which is when the gradients used for updating the weights in a neural network shrink exponentially during the backpropagation process, which makes the early layers stop learning from the inputs.
.jpg)
3. Pooling
- Pooling
is a spatial downsampling technique, with the most common variant being
max pooling.
- This means taking the maximum value from a small local region (like a grid).
- This reduces the size of the feature map, which reduces the computational
cost of the network.
- This, in turn, helps the model focus on the most important features of the input and introduces a degree of translation invariance, which is the robustness to small shifts in the input image.
.jpg)
Pixels to Objects
Inspired by biological visual cortex models, deep learning models build a progressive hierarchical feature representation. This means computer vision systems gradually go from raw input data to meaningful object understanding.
The progression is as follows:
Pixels → Edges → Shapes / Parts → Objects
- The first layer acts similarly to manual edge detectors by extracting local edges, which are the fundamental boundaries in visual data.
- The second layer will then combine these edges into corners or object parts.
- Finally, the higher layers compute more global, abstract, and invariant features capable of recognizing entire objects.
Edge detection in this context is important for visual understanding in CNNs and deep architectures, as it highlights meaningful boundaries in images that correspond to objects.
.jpg)
.jpg)
.jpg)
.jpg)
Training and Transfer
CNNs are supervised learning models that compute classification error using an algorithm called backpropagation, which updates the network's weights through gradient descent.
Training deep networks from scratch requires massive amounts of data, time, and compute, which is why they rely on what is called transfer learning.
Transfer learning means reusing a neural network trained on a large dataset (such as ImageNet) and adapting it to a new task.
- The earlier layers of a CNN learn foundational visual features such as edges and textures, which are useful across many different visual tasks.
- When we take a pre-trained network and "fine-tune" the last few layers on a new, smaller dataset, practitioners can save significant training time and achieve better performance compared to when they try to relearn it all from scratch.
Tl;dr
Old CV
- Relied on hand-crafted features designed by engineers.
- Used techniques like manual edge detection.
- Built on shallow systems with a small number of processing stages.
New CV / CNNs
- Built using deep architectures.
- Designed to learn features automatically from data.
- Extracts higher-level representations from raw images without human feature engineering.
CNN building blocks
- Convolution — detects local patterns with shared filters.
- ReLU — adds nonlinearity, turns negatives into .
- Pooling — downsamples and helps with translation robustness.
Vision hierarchy
- Processes data sequentially: Pixels → edges → shapes and object parts → objects.
Transfer learning
- Allows you to reuse a pre-trained network for a new task.
- This strategy saves time and often improves performance.
References
- Das, S. Deep Learning — Convolutional Neural Networks (Lectures 8–10). ITCS-4152 / ITCS-5010 Computer Vision course lecture slides.
- AtAI.fi. CNN (Convolutional Neural Network). AI glossary. Last reviewed Jan 17, 2026.